Key to the widespread adoption of embedded vision is the ease of developing software that runs efficiently on a diversity of hardware platforms, with high performance, low power consumption and cost-effective system resource needs. In the past, this combination of objectives has been a tall order, since it has historically required significant code optimization for particular device architectures, thereby hampering portability to other architectures. Fortunately, this situation is changing with the maturation of the OpenVX standard created and maintained by the Khronos Group. This article discusses recent evolutions of the standard, along with the benefits and details of implementing it on heterogeneous computing platforms.
OpenVX, an API from the Khronos Group, is an open standard for developing high performance computer vision applications that are portable to a wide variety of computing platforms. It uses the concept of a computation graph to abstract the compute operations and data movement required by an algorithm, so that a broad range of hardware options can be used to execute the algorithm. An OpenVX implementation targeting a particular hardware platform translates the graph created by the application programmer into the instructions needed to execute efficiently on that hardware. Such flexibility means that the programmer will not need to rewrite his or her code when re-targeting new hardware, or to write new code specific to that hardware, making OpenVX a cross-platform and heterogeneous computing-supportive API.
A previously published article in this series covered the initial v1.0 OpenVX specification and provided an overview of the standard’s objectives, along with an explanation of its capabilities, as they existed in early 2016. This follow-on article focuses on more recent updates to OpenVX, up to and including latest v1.2 of the specification and associated conformance tests, along with the recently published set of extensions that OpenVX implementers can optionally provide. It also discusses the optimization opportunities available with SoCs’ increasingly common heterogeneous computing architectures. And it introduces readers to an industry alliance created to help product creators incorporate practical computer vision capabilities into their hardware and software, along with outlining the technical resources that this alliance provides (see sidebar “Additional Developer Assistance“).
A companion article showcases several case study examples of OpenVX implementations in various applications, leveraging multiple hardware platforms along with both traditional and deep learning computer vision algorithms.
OpenVX Enhancements
The following section was authored by Cadence, representing Khronos’ OpenVX Working Group.
The primary additions to the OpenVX API found in v1.2 involve feature detection, image processing, and conditional execution. Version 1.2 also introduces the tensor object (vx_tensor), which has been added primarily in support of the neural network extension but is also used in several of the new base functions. In addition to explaining these new capabilities, this section will discuss several recently defined extensions, including functionality for image classification (using both traditional and deep-learning methods) and safety-critical applications.
New Feature-detection Capabilities
The feature-detection capabilities found in OpenVX v1.2 include the popular histogram of oriented gradients (HOG) and local binary pattern (LBP) detectors, along with template matching and line finding. These algorithms are useful in tasks such as pedestrian detection, face recognition and lane detection for advanced driver assistance systems (ADAS).
HOG is implemented in OpenVX via two main functions, vxHOGCellsNode and vxHOGFeaturesNode. The vxHOGCellsNode function divides an input image into a number of grid cells and calculates the HOG information for each cell, which consists of gradient orientation histograms and average gradient magnitudes. This is a measure of how much “edge” there is in each cell and the direction of the edges. The information computed by vxHOGCellsNode for these cells can then be fed into a vxHOGFeaturesNode function, which looks at groups of cells and computes HOG “descriptors” that describe the pattern of edges in each area of the image. A set of these descriptors is sometimes called a “feature map.”
The feature map is then fed into a classifier that has been trained to tell if the pattern matches what you’re looking for (such as pedestrians). OpenVX offers a classifier API as an extension, with functions to import, use, and release a classifier object. The extension includes a vxScanClassifierNode function to create an OpenVX node that takes a feature map as input and outputs a list of rectangles around the detected objects (Figure 1).
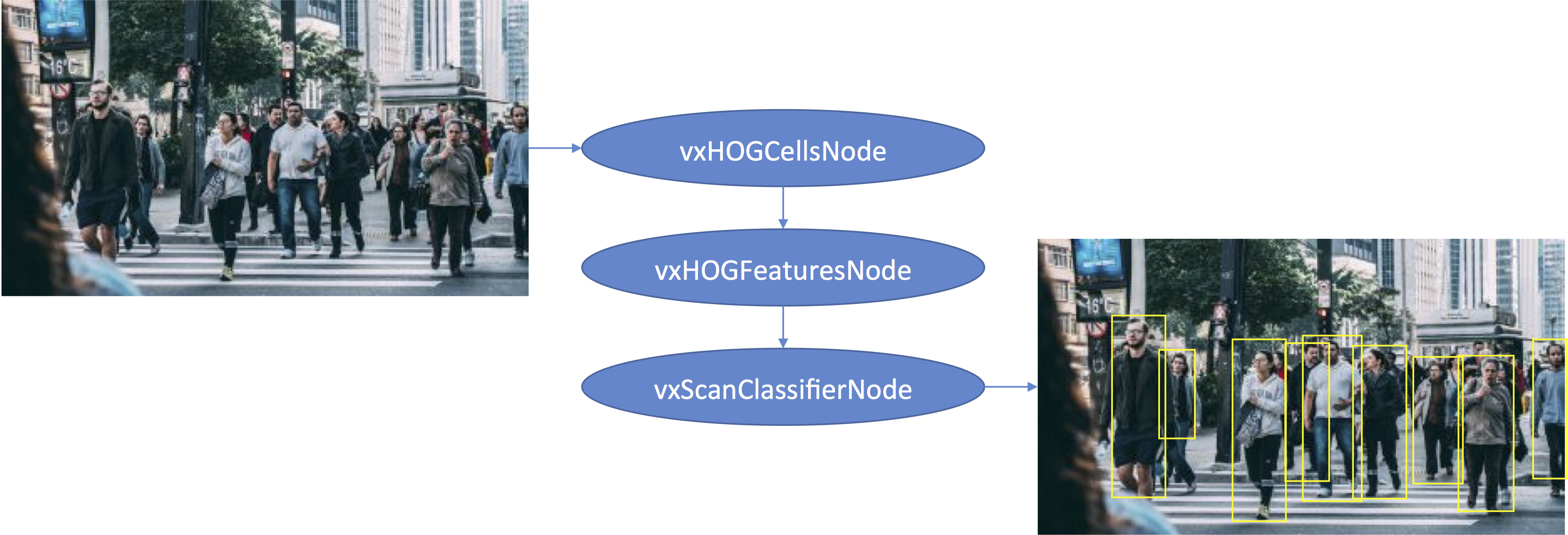
Figure 1. OpenVX’s classifier API extension includes a function that takes a feature map as input and outputs a list of rectangles around the detected objects (courtesy Pexels).
LBP is useful for detecting objects, sometimes in conjunction with HOG, as well as in texture classification and face recognition. The OpenVX node for LBP is vxLBPNode, which takes an input image and a few tuning parameters and outputs an image of the same size with the value of the LBP descriptor at every point in the image.
The template matching function compares two images and computes a measure of their similarity. One of the input images is referred to as the source image, and the other, typically much smaller image is referred to as the template image. The corresponding OpenVX function is vxMatchTemplateNode; like many OpenVX functions, it is based on a similar function in OpenCV. vxMatchTemplateNode takes as input the source and template images, plus a parameter that indicates which of six available comparison functions to use. It outputs an image in which each pixel is a measure of the similarity of the template to the source image at that point in the source image.
The line-finding feature detector in OpenVX v1.2 implements the probabilistic Hough transform. The function, called vxHoughLinesPNode, takes an image and various tuning parameters as inputs, outputting a list of detected lines.
New Image-processing Features
OpenVX v1.2 adds three useful image-processing functions: a generalized nonlinear filter, non-maximum suppression, and a bilateral filter. These image-processing functions have images as both their input and output, and are often used to enhance image quality or refine feature map images.
The vxNonLinearFilterNode generalized nonlinear filter function accepts, in addition to the input and output image parameters, two additional input parameters, “mask” and “function,” to describe the specific filter desired. The mask parameter defines the shape of the filter, which can be a box, cross, a disk of various sizes, or even an arbitrary shape defined by the user.
The available choices for the function parameter are median, min and max. The median filter is a standard image-processing operation usually used to reduce noise. For each pixel in the output image, the median value within the area of the input image defined by the mask is taken to be the output value. The procedure for the min and max functions is similar, but with the substitution of the min or max value instead of the median value. The max function corresponds to the standard dilate image-processing operation, while the min function corresponds to erode. Dilate and erode are usually used to refine and clean up binary images, but can be applied to gray-scale images as well.
The non-maximum suppression image-processing function is generally used on the output images from feature detectors, which often highlight several pixels in the area of a feature detection. Non-maximum suppression reduces these clumps of detections into a single detection at the maximum point. The associated OpenVX function, vxNonMaxSuppressionNode, accepts an input image, a “window” parameter, and an optional mask to limit where the suppression is performed. It produces an output image with all of the pixels in a clump except for the maximum value in the clump set to zero or the most negative value.
A bilateral filter is a popular image-processing operation that is often referred to as “edge-preserving,” because it can significantly reduce noise and smooth an image without blurring the edges. The associated OpenVX function is vxBilateralFilterNode. The input and output images for this function are encapsulated in the new vx_tensor object, since the bilateral filter can operate on multiple image channels. In addition to the input image, the user provides the bilateral filter with tuning parameters for “diameter” and “sigma” to control the degree of smoothing.
Control Flow and Conditional Execution
Support for control flow and conditional execution is the major new framework feature introduced in OpenVX v1.2. Until now, during graph execution, all nodes in the graph were executed every time the graph was processed, potentially adding unnecessary processing overhead to the application. Conversely, the new control flow and conditional execution features included in OpenVX v1.2 allow the OpenVX application to check various conditions and determine what processing to perform based on them. Prior to OpenVX v1.2, control flow operations could only be executed on the host processor. The conditional execution feature of OpenVX v1.2 enables execution of an if-then-else control flow on the target hardware without need for intervention from the host processor.
The conditional execution feature is implemented in OpenVX v1.2 via the vxScalarOperationNode and vxSelectNode functions. vxScalarOperationNode enables the user to construct and test conditions using simple arithmetic and logical operations such as add, subtract, and, or, etc. It takes two scalar input operands and an operation type as input, and produces a scalar output. Such nodes can be combined to produce arbitrary expressions. vxSelectNode takes as input a Boolean object, which is usually the output of a vxScalarOperationNode operation, along with three object references: a true value, a false value and an output object. These references must all be to objects of the same type and size. When the graph containing these nodes is executed, depending on the value of the Boolean object, either the true value or the false value is copied into the output object (Figure 2).
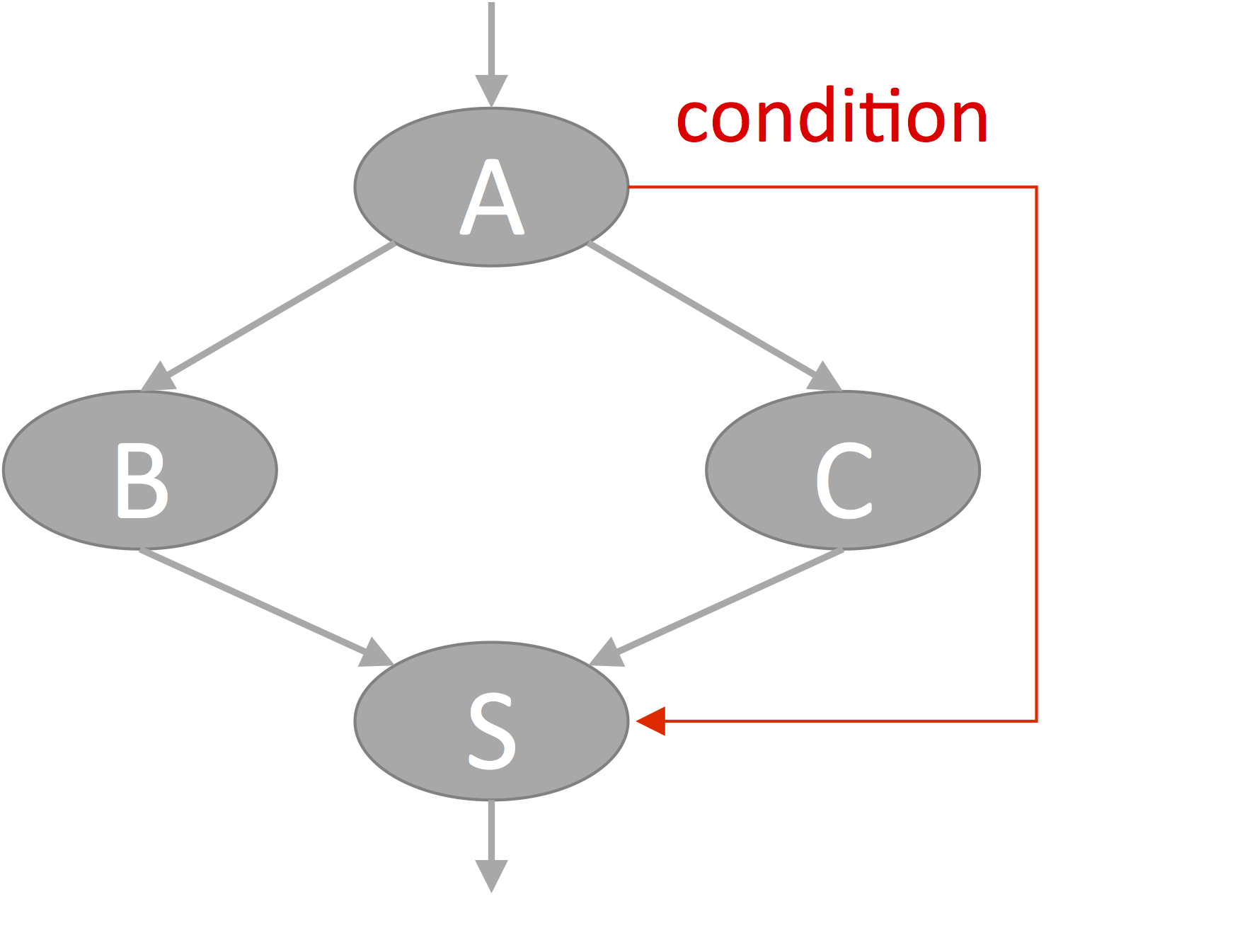
Figure 2. Support for control flow and conditional execution is the major new framework feature introduced in OpenVX v1.2 (courtesy Cadence).
The subgraph in Figure 2 forms an if-then-else structure, where, depending on the condition calculated in A, the output of the select node S is either the output of B or the output of C. In other words, if A then S ← B, else S ← C. The OpenVX implementation, in analyzing this subgraph can notice that if the condition is true, the output of C is not used, so node C doesn’t need to be executed (and analogously, if A is false, B doesn’t need to be executed). In this particular example, B and C are just single nodes, but this facility can more generally be used to skip arbitrary chains of nodes based on conditions computed in the graph, again potentially without intervention by the host processor.
Finally, as mentioned earlier where it was used in the bilateral filter function, OpenVX v1.2 introduces a vx_tensor object. The base specification for OpenVX 1.2 includes functions to element-wise add and subtract tensors, do an element-wise table lookup, transpose, matrix multiply, and perform bit-depth conversion on tensors. The neural network extension to be discussed shortly also uses the vx_tensor object extensively.
Frank Brill
Design Engineering Director, Cadence Design Systems
OpenVX Extensions
The following section was authored by Intel, representing Khronos’ OpenVX Working Group.
Successful ongoing development of the main OpenVX specification is dependent on stability and consensus, both of which take notable time and effort. However, when a technology is developing rapidly, engineers benefit from a fast path to product development. In response, Khronos has created the extensions mechanism to rapidly bring new features to fruition. Khronos extensions still go through a ratification process, but its streamlined nature in comparison to the main specification can dramatically shorten the availability wait time.
To date, the OpenVX Working Group has published multiple extensions, in both finalized (Table 1) and provisional (Table 2) forms.
| Extension Name |
OpenVX Versions |
Description |
| vx_khr_nn | 1.2 | Neural network extension |
| vx_khr_ix | 1.2, 1.1 | Export and import extension for graphs & objects |
Table 1. OpenVX Finalized Extensions
| Extension Name |
OpenVX Versions |
Description |
| vx_khr_import_kernel | 1.2, 1.1 | Import kernel from vendor binary |
| vx_khr_pipelining | 1.2, 1.1 | Pipelining, streaming, and batch processing extension |
| vx_khr_opencl | 1.2, 1.1 | OpenCL interop extension |
| vx_khr_class | 1.2 | Classifier extension |
| vx_khr_s16 | 1.1 | S16 extension |
| vx_khr_tiling | 1.0 | Tiling extension |
| vx_khr_xml | 1.0 | XML schema extension |
| vx_khr_icd | 1.0 | Installable client driver extension |
Table 2. OpenVX Provisional Extensions
Neural Network Extension
The neural network extension enables the use of convolutional neural networks (CNNs) inside an OpenVX graph. The neural network layers are represented as OpenVX nodes, connected by multi-dimensional tensor objects. Supported layer types include convolution, activation, pooling, fully-connected, soft-max, etc. These CNN nodes can also mix with traditional vision algorithm nodes (Figure 3).
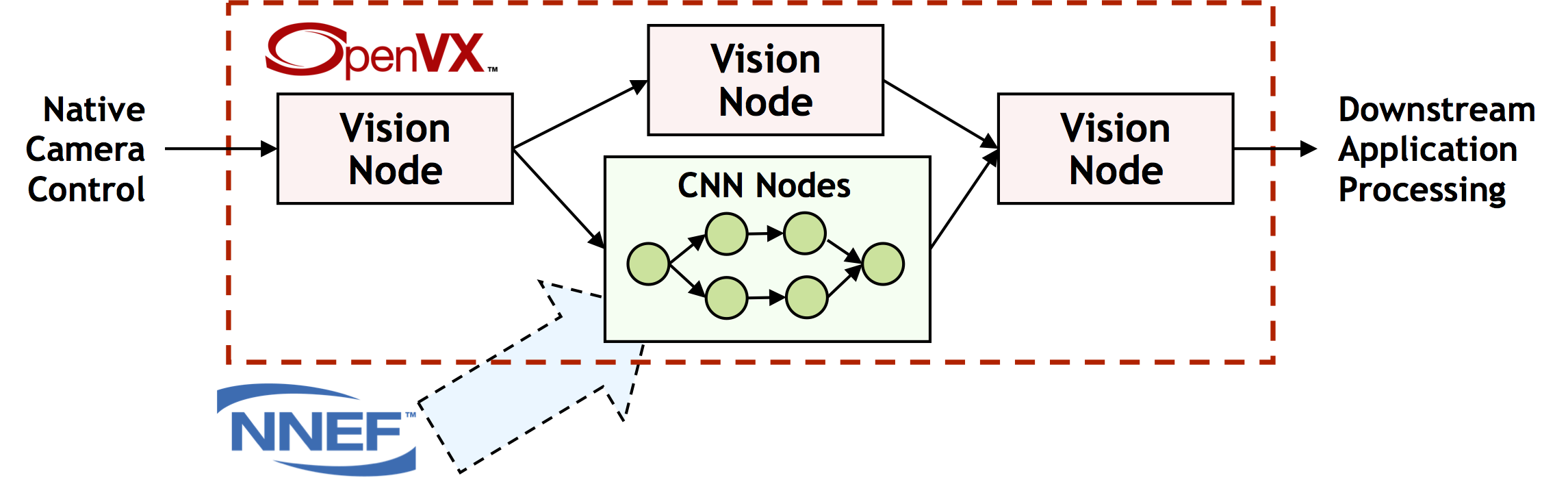
Figure 3. OpenVX graphs can mix CNN nodes with traditional vision nodes (courtesy Khronos).
With cost- and power consumption-sensitive embedded system targets in mind, implementations of this extension must support tensor data types INT16, INT7.8, and UINT8. Conformance tests will allow for some tolerance in precision in order to enable optimizations such as weight compression. Example supported networks include Overfeat, AlexNet, GoogLeNet, ResNet, DenseNet, SqeezeNet, LSTM, RNN/BiRNN, Faster-RCNN, FCN, and various Inception versions.
Export and Import Extension
Every OpenVX implementation comes with both a graph optimizer and an execution engine. The graph optimizer can be computationally “heavy,” akin to running a compiler. Its use is therefore not only burdensome but also unnecessary for use cases such as the following:
- Embedded systems which use fixed graphs to minimize the required amount of code
- Safety-critical systems where the OpenVX library does not have a node creation API
- CNN extensions that require ability to import pre-compiled binary objects
Alternatively, to optimize OpenVX for use cases such as these, Khronos first subdivides the overall OpenVX workflow into “development” and “deployment” stages (Figure 4). The export and import extension provides mechanisms both to export a pre-compiled binary from the development stage and to import the pre-compiled binary into a deployed application.

Figure 4. The overall OpenVX workflow subdivides into development and deployment stages (courtesy Khronos).
Provisional Extensions
Several OpenVX provisional extensions have already been developed by the OpenVX Working Group, with others to potentially follow. Provisional extensions, as their name implies, provide a means for engineers to begin their implementation development and provide feedback to the OpenVX Working Group before the extension specification is finalized. Recent provisional extensions include the pipelining extension, the OpenCL interop extension, the kernel import extension, and the classifier extension.
Heterogeneous computing architectures are increasingly dominant in modern devices. Obtaining peak utilization and throughput from heterogeneous hardware requires the ability to schedule multiple jobs by means of pipelining or batching. The pipelining extension provides a mechanism to feed multiple values to a given graph input simultaneously or in a stream, enabling the implementation to achieve higher hardware utilization and throughput. An example OpenVX graph and mapping of its nodes to heterogeneous parallel hardware demonstrates this capability (Figure 5). Graph execution without pipelining will result in underutilization of compute resources, with consequent sub-optimal throughput. Conversely, pipelining will deliver higher throughput and utilization.
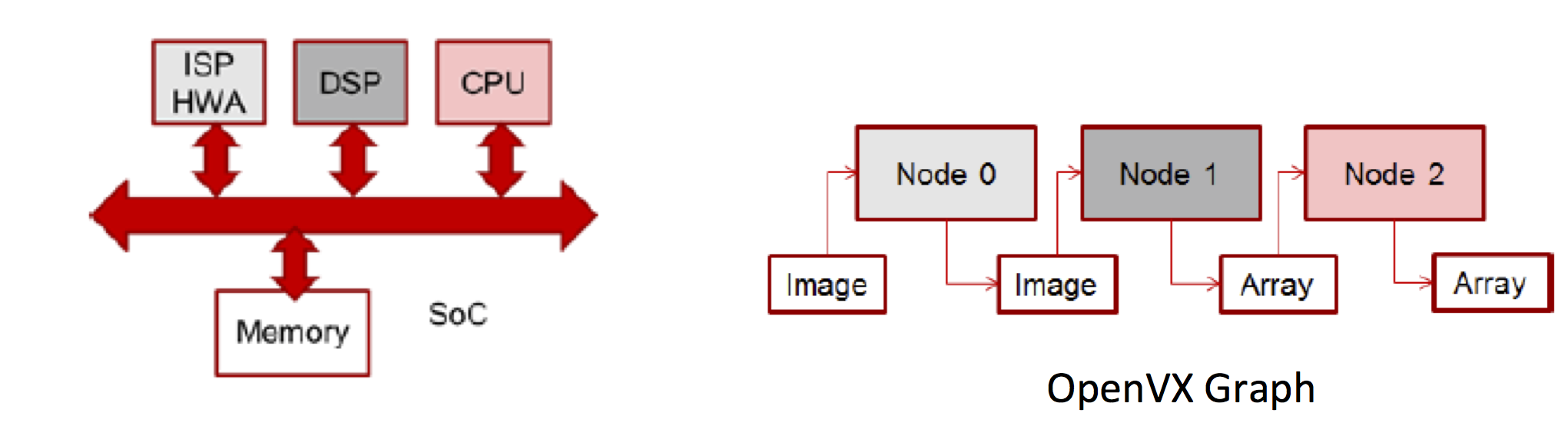
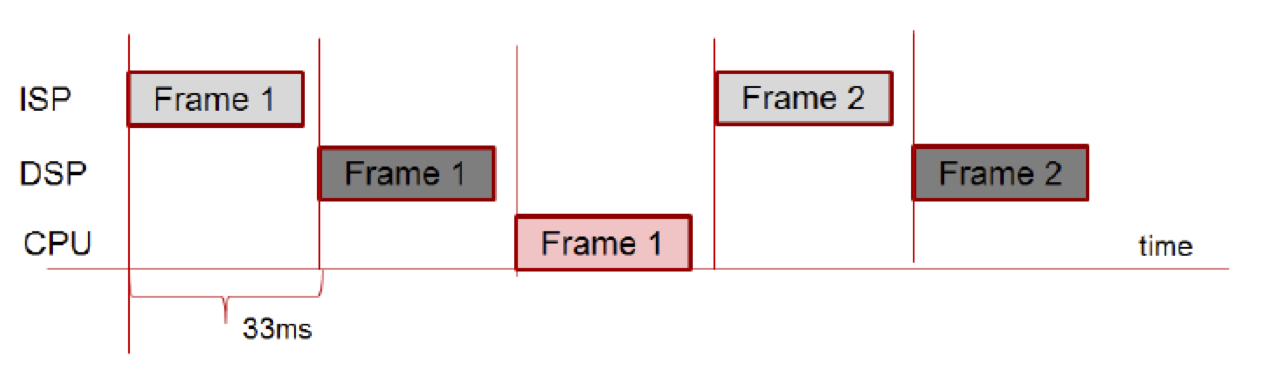
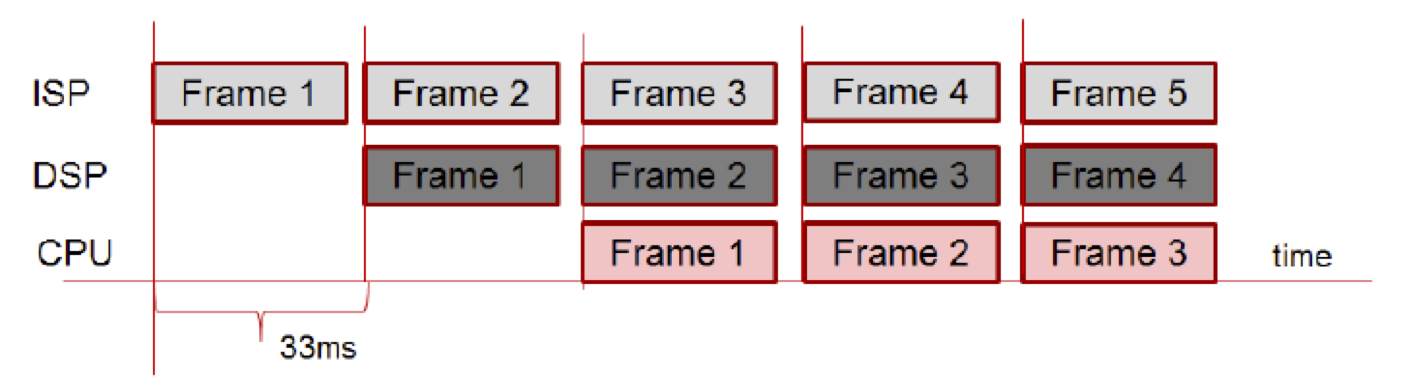
Figure 5. This example demonstrates mapping of nodes to hardware (top). OpenVX graph execution without pipelining will result in underutilization of compute resources, with consequent sub-optimal throughput (middle). Conversely, pipelining will deliver higher throughput and utilization (bottom) (courtesy Khronos).
The OpenCL interop extension enables efficient data exchange between OpenVX and an OpenCL application or user kernel. Using the interop extension, an OpenCL-based application will be able to efficiently export OpenCL data objects into the OpenVX environment, as well as to access OpenVX data objects as OpenCL data objects. Another key feature is fully asynchronous host-device operation, an important capability for data exchanges.
The kernel import extension provides a means of importing an OpenVX kernel from a vendor binary URL. Unlike the previously discussed export and import extension, this extension (as its name suggests) only focuses on importing kernel objects, which can be sourced directly from vendor-specific binaries pre-compiled offline using either vendor- or third-party-supplied toolsets. One compelling example use case for this extension involves importing a pre-compiled neural network model as an OpenVX kernel object, which can then be instantiated in multiple different graphs.
Finally the classifier extension enables the deployment of an image classifier that can support methods such as support vector machine (SVM) and Cascade (Decision Tree).
Radhakrishna Giduthuri
Deep Learning Architect, Intel
OpenVX and Heterogeneous SoCs
The prior section of this article conceptually discussed the benefits of, and extension mechanisms available in supporting, heterogeneous computing architectures containing multiple parallel and function-optimized processing elements. The following section, authored by NXP Semiconductors, discusses an example implementation of the concept based on the company’s SoCs targeting ADAS (advanced driver assistance systems) and fully autonomous vehicles.
The large-scale deployment of vision-based ADAS and autonomous vehicle technology is made possible through the use of specialized SoCs that meet the automotive quality, performance, functionality, availability, and cost targets required by OEMs. These specialized SoCs, such as the NXP S32V family, are highly heterogeneous in nature, including (for example) multiple ARM processor cores, both programmable and hardwired vision accelerators, and GPUs (Figure 6). Programming such SoCs to optimally leverage all available resources is not trivial. Fortunately, OpenVX offers a number of benefits that make the task much easier.
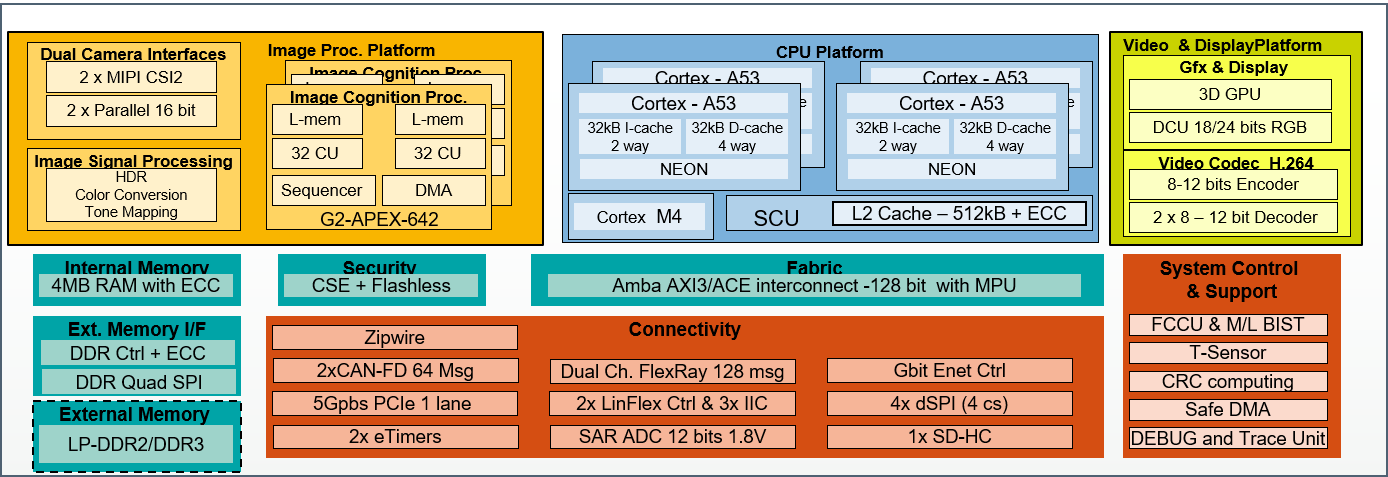
Figure 6. Highly integrated SoCs provide abundant heterogeneous computing opportunities (courtesy NXP Semiconductors).
The development of vision algorithms on ARM processor cores and the GPU is relatively straightforward, enabled by the use of standard programming languages and APIs. However, vision accelerators (both programmable and hardwired) are largely proprietary architectures. Even if an accelerator supplier provides a custom library or API with explicit names for various vision processing operations, it can be difficult to assess what result is actually provided by these functions, as many variations are possible. This variety is particularly of concern when the goal is an optimized implementation of various computer vision algorithms.
In contrast, since the foundation OpenVX API includes both well-defined specifications and conformance tests, a user will know exactly what results to expect from all computer vision operations defined by OpenVX (note, however, that OpenVX provisional extensions are not similarly encompassed by formal conformance). Leveraging the OpenVX standard API as a hardware abstraction layer enables users to straightforwardly invoke proprietary vision processing hardware, assuming it provides OpenVX conformance, with full confidence in their results.
Inherent in this process is the optional ability, for performance and load balancing reasons, to explicitly indicate which heterogeneous SoC resource should perform a particular computation. A user might designate an Optical Flow Pyramid function to run on a vision accelerator, for example, while a Table Lookup function concurrently executes on one or multiple ARM cores. Recall that an OpenVX graph is a collection of vision function nodes connected by data objects (e.g., images). A node encapsulates a kernel, which is an implementation of a vision function on a specific target. And a target can either be physical (such as a GPU, CPU or vision accelerator) or logical. The target of a particular node may either be explicitly specified by the developer or dynamically selected by the framework at graph verification time.
In the context of ADAS and autonomous vehicles, it’s also important to note the availability of a safety critical (SC) version of the OpenVX specification. The SC variant of the standard enables implementations that meet ISO 26262 functional safety requirements. One key aspect of this version of OpenVX is its ability to import pre-verified graphs, meaning that no runtime graph build system validation is required. OpenVX SC also removes the vxu library (which invokes a runtime graph build); such operations need to be avoided for functional safety purposes.
Stéphane François
Software Program Manager, Vision and AI R&D, NXP Semiconductors
Conclusion
Vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. Vision processing can add valuable capabilities to existing products, and can provide significant new markets for hardware, software and semiconductor suppliers. Key to the widespread adoption of embedded vision is the ease of developing software that runs efficiently on a diversity of hardware platforms, with high performance, low power consumption and cost-effective system resource needs. In the past, this combination of objectives has been challenging, since it has historically required significant code optimization for particular device architectures, thereby hampering portability to other architectures. Fortunately, this situation is changing with the maturation of the OpenVX standard created and maintained by the Khronos Group.
Brian Dipert
Editor-in-Chief, Embedded Vision Alliance
Senior Analyst, BDTI
Sidebar: Additional Developer Assistance
The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform the potential of vision processing into reality. Cadence Design Systems, Intel, NXP Semiconductors and VeriSilicon, the co-authors of this series of articles, are members of the Embedded Vision Alliance. The Embedded Vision Alliance’s mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Embedded Vision Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Embedded Vision Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance’s annual technical conference and trade show, the Embedded Vision Summit, is intended for product creators interested in incorporating visual intelligence into electronic systems and software. The Embedded Vision Summit provides how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Embedded Vision Alliance member companies. The Embedded Vision Summit is intended to inspire attendees’ imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings. The next Embedded Vision Summit is scheduled for May 20-23, 2019 in Santa Clara, California. Mark your calendars and plan to attend; more information, including online registration, will be available on the Embedded Vision Alliance website in the coming months.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Embedded Vision Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV, along with Caffe, TensorFlow and other machine learning frameworks. Access is free to all through a simple registration process. And the Embedded Vision Alliance and its member companies also periodically deliver webinars on a variety of technical topics. Access to on-demand archive webinars, along with information about upcoming live webinars, is available on the Embedded Vision Alliance website.